15. Trees
CAUTION - CHAPTER UNDER CONSTRUCTION!
NOTICE: If you are NOT enrolled in the CSC 230 course that I teach at SFSU, you probably are looking for the “public version” of the book, which I only update between semesters. The version you are looking at now is the “CSC230 version” of the book, which I will be updating throughout the semester.
This chapter was last updated on May 4, 2026.
Fixed some typos.
Inserted links and very brief mention of depth-first and breadth-first traversals.
Added more content to the section on binary trees: Tree traversal algorithms, Łukasiewicz’s parentheses-free notation (“Polish notation”) and expression trees.
Revised section on directed trees. Rewrote theorem on second characterization of trees.
A tree is a connected simple graph that contains no cycles. Trees are used to model decisions, to sort data, and to optimize networks.
Key terms and concepts covered in this chapter:
-
Trees
-
Definition of “tree” and “forest”
-
Properties of trees
-
Spanning trees
-
Binary trees
-
Traversal strategies
-
Expression trees
-
-
15.1. Definitions, Examples, and Properties of Trees and Forests
In this section, you will learn some of the basics about trees.
| Much of the terminology related to trees is not standardized, that is, different textbooks and sources use different terminology for the same types of trees. The Remix uses terminology consistent with Handbook of Graph Theory, Second Edition by Gross, Yellin, and Zhang. |
Recall that a simple graph has no loops and no parallel edges.
Also, recall that a cycle in a graph is a path that starts and ends at the same vertex.
A tree is a simple graph that is connected and has no cycles. Some sources use the term acyclic to mean "has no cycles."
A forest is the union of several trees. In other words, a forest is a simple graph that has one or more connected components, where each connected component is a tree.
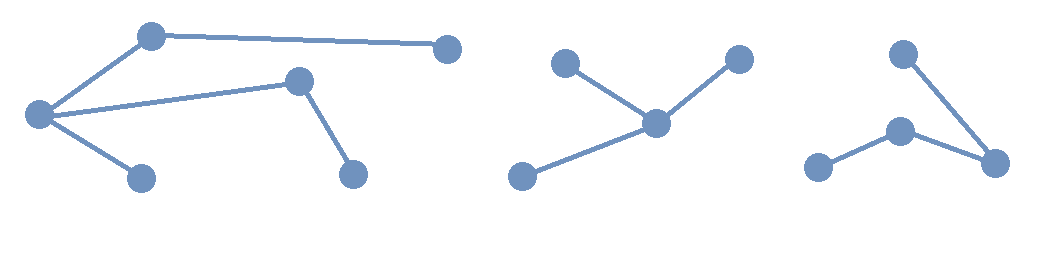
The image shows a forest composed of three trees.
Notice that if you choose any pair of vertices in one of the trees in the image, there is only one path that joins that pair of vertices. In fact, this property is True for any tree.
Next, we will give another characterization of trees, after first proving a lemma.
15.2. Spanning Trees and Spanning Forests
Recall that a subgraph of a graph \(G\) is a graph \(H\) such that every vertex of \(H\) is a vertex of \(G\) and every edge of \(H\) is a edge of \(G\) (with both endpoints in the vertex set of \(H.\))
A subtree of a graph \(G\) is a subgraph of \(G\) that is also a tree. Likewise, a subforest of \(G\) is a subgraph of \(G\) that is also a forest.
A spanning tree of a graph \(G\) is a subgraph of \(G\) that is a tree that includes all the vertices of \(G.\) Likewise, a spanning forest of a graph \(G\) is a subgraph of \(G\) that is a forest that includes all the vertices of \(G.\)
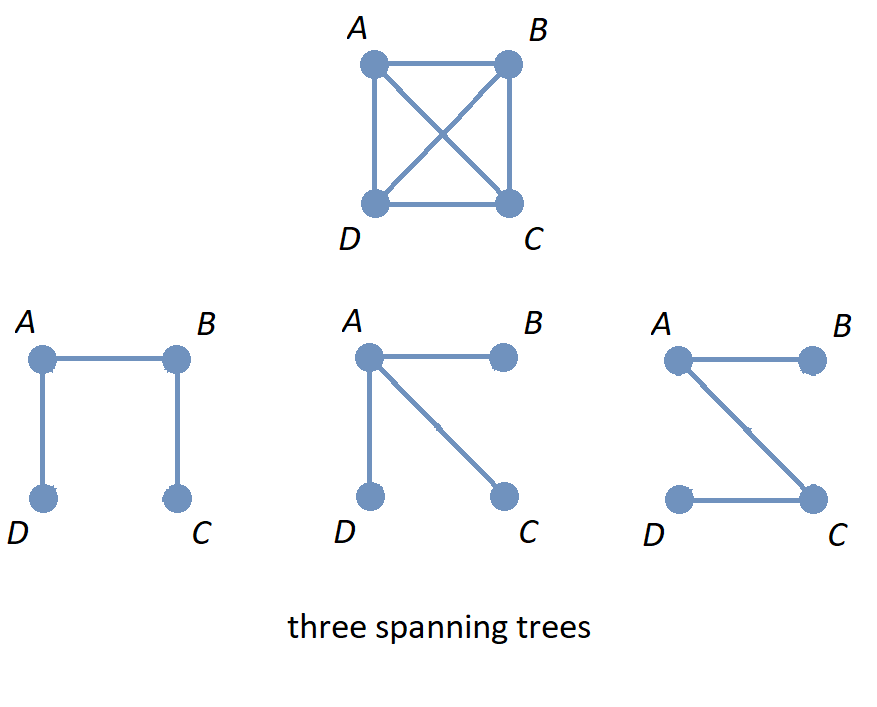
The image shows the graph \(K_{4}\) along with three spanning trees.
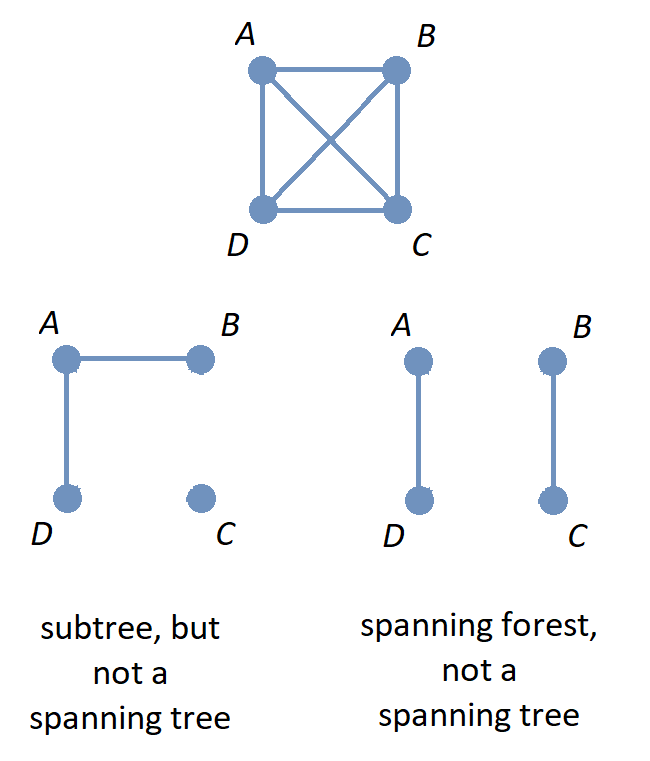
The image shows the graph \(K_{4}\) along with a subgraph that is a subtree that is not a spanning tree, and also a subgraph that is a spanning forest.
Spanning trees are used to solve problems that involve simplifying or optimizing networks. You can learn more about some of the applications of spanning trees at this Wikipedia page.
The following subsection presents one such application.
15.2.1. Minimal-Weight Spanning Trees in Weighted Graphs
In some applications of graphs with weighted edges, you may need to find a spanning tree that has the minimal total weight possible, that is, a spanning tree with sum of edge weights less than or equal to the corresponding sum for any other spanning tree.
Such a spanning tree is referred to as a
minimal-weight spanning tree.
Note: Many textbooks and sources use the term
minimum length spanning tree
because the use of these spanning trees historically arose in problems that involved physical distances between nodes of a network. Other sources use the term
minimum spanning tree,
abbreviated as
MST.
As an example, the image shows a weighted graph along with all three possible spanning trees. The minimal-weight spanning tree, with total weight 6, is drawn on the lower left.
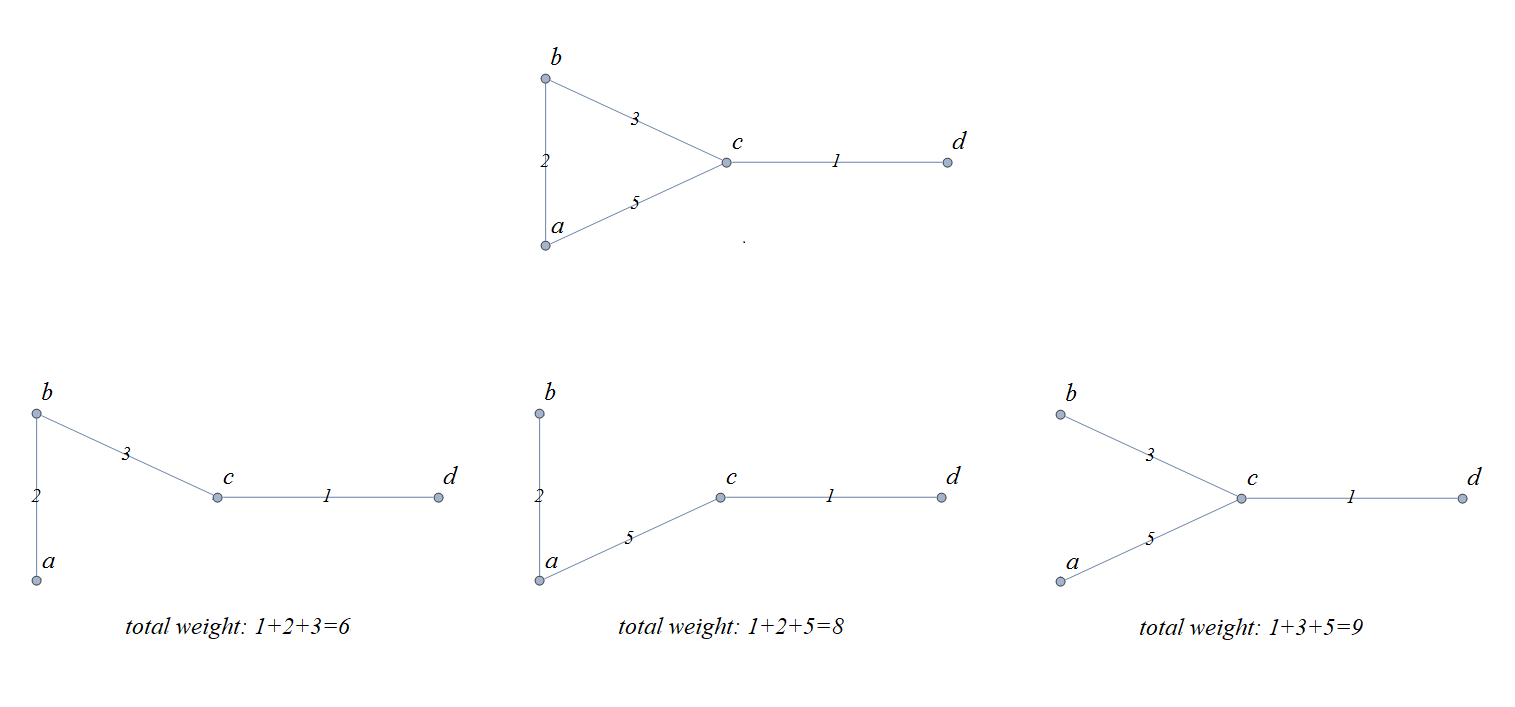
Notice that for the graph in the image, it was both easy and efficient to use “brute force” to look at all of the spanning trees and compute all of the sums of weights for those spanning trees. For weighted graphs that have many more vertices and/or edges, you will need to use a more efficient problem-solving strategy. This textbook discusses one such strategy, Kruskal’s algorithm, in detail.
Kruskal’s Algorithm
Joseph Kruskal published a paper in 1956 that describes an algorithm for constructing “the shortest spanning subtree” of a connected simple graph (Kruskal assumed that the graph has only finitely-many edges, and that each edge has a positive weight which represents the distance between its endpoints.)
-
Task: Given a connected graph \(G = (V,E)\) with weighted edges, construct a spanning tree of \(G\) that has the minimal possible sum of weights.
-
Input: The list \(E\) of all weighted edges of the graph.
-
Steps:
-
Sort the list of edges \(E\) so that each edge \(e_{k}\) in the list has a weight that is less than or equal to the next edge \(e_{k+1}\) in the list.
-
Define the list \(E_{chosen}\) and initialize it as an empty list.
-
Set integer index variable \(i\) to 0.
-
While \(i\) is less than \(|E|,\) the number of edges
-
If it is impossible to form a cycle using edge \(e_{i}\) along with some (or all) of the edges in list \(E_{chosen}\)
-
Append \(e_{i}\) to \(E_{chosen}\)
-
-
Increment \(i\) by 1
-
-
-
Output: The list \(E_{chosen}\) of weighted edges.
Notice that the output list \(E_{chosen}\) was constructed so that its edges cannot be used to form a cycle in the graph \(G.\) Also, since the graph \(G\) is assumed to be connected, every vertex will be the endpoint of at least one edge in \(E_{chosen},\) so that the graph with vertex set \(V\) and edge set \(E_{chosen}\) will be a spanning tree of \(G.\)
Also notice that the condition for the while loop can be changed to “while \(|E_{chosen}| < |V| - 1\)” since a spanning tree must have one fewer edges than vertices.
The image shows a drawing of a simple weighted graph along with all three possible spanning trees.
The minimal-weight spanning tree, with total weight 6, is drawn on the lower left.
Let’s trace through the steps of Kruskal’s algorithm to examine how this minimal-weight spanning tree is constructed. The following table represents the input to the algorithm: A list of all the edges of the graph, along with their corresponding weights.
| Edge | Weight |
|---|---|
|
{c, d} |
1 |
|
{a, b} |
2 |
|
{b, c} |
3 |
|
{a, c} |
5 |
-
Steps:
-
Sort the list of edges of the graph in order of increasing weight (This has already been done in the table shown.)
-
Set \(E_{chosen}\) to the empty list.
-
Set the index \(i\) to 0.
-
Enter the while loop.
- \(i=0\)
-
\(i\) is less than 4, and it is impossible to form a cycle using \(\{c, d\}\) alone,
so set \(E_{chosen}\) to \([\{c, d\}\)] and set \(i\) to 1. - \(i=1\)
-
\(i\) is less than 4, and it is impossible to form a cycle using \(\{a, b\}\) along with the edge in \(E_{chosen} = [\{c, d\}\)]
so set \(E_{chosen}\) to \([\{c, d\} , \{a, b\}\)] and set \(i\) to 2. - \(i=2\)
-
\(i\) is less than 4, and it is impossible to form a cycle using \(\{b, c\}\) along with the edges in \(E_{chosen} = [\{c, d\} , \{a, b\}\)]
so set \(E_{chosen}\) to \([\{c, d\} , \{a, b\}, \{b, c\}\)] and set \(i\) to 3. - \(i=3\)
-
\(i\) is less than 4, but it is possible to form a cycle using \(\{a, c\}\) along with the edges in \(E_{chosen} = [\{c, d\} , \{a, b\}, \{b, c\}\)]
so make no change to \(E_{chosen}\) and set \(i\) to 4. - \(i=4\)
-
Since \(i\) is not less than 4, exit the while loop.
-
The output is \(E_{chosen} = [\{c, d\} , \{a, b\}, \{b, c\}\)] which is the list of edges used in the spanning tree drawn on the lower left of the image. That is, in at least this one case, the algorithm does construct a minimal-weight spanning tree.
That is, how could you prove that Kruskal’s algorithm must construct a minimal-weight spanning tree for any input graph that is connected and has finitely-many weighted edges?
Here is an exercise for you to try.
Use Kruskal’s algorithm to find the minimal-weight spanning tree for the following graph.
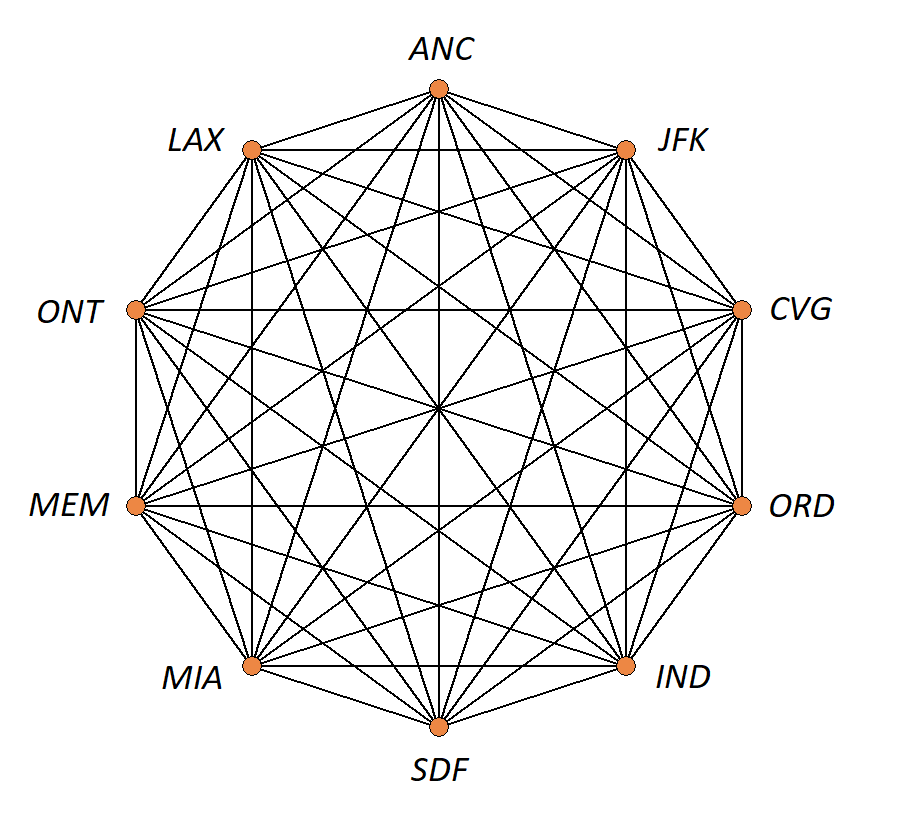
The image shows a graph with vertices representing ten of the busiest airports, by total cargo throughput, in the United States of America. Each vertex is labeled with the International Air Transport Association code for one of the airports, and
each edge represents the route between the two airports at the endpoints.
Image credit: Remixer-created derivative of original work
"9-simplex graph.png"
. The original work has been released into the public domain by its author, Tomruen at English Wikipedia. This applies worldwide.
{kind=link}
This table lists each edge with its corresponding weight.
You can download the table as a tab-delimited text file to import the data into a spreadsheet app to sort the list.
You also can view the graph as a map of the routes between the airports at Markus Englund’s Great Circle Map website.
Try to work this out on your own, then confirm that you correctly found the minimal-weight spanning tree by clicking to see the answer below.
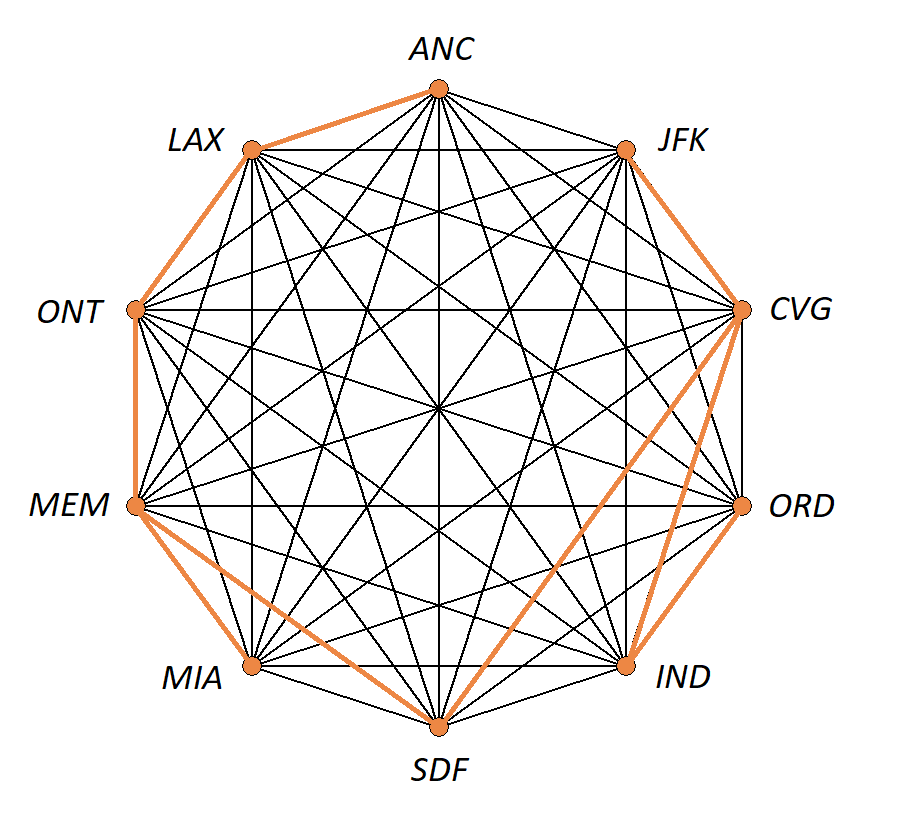
Image credit: Remixer-created derivative of original work "9-simplex graph.png" . The original work has been released into the public domain by its author, Tomruen at English Wikipedia. This applies worldwide.
The table lists the edges of the minimal-weight spanning tree. + +
A map view of the minimal-weight spanning tree can be seen at the Great Circle Map website.
Other Algorithms for Minimal-Weight Spanning Trees
Among the other algorithms that can be used to find a minimal-weight spanning tree are Borůvka’s algorithm and Prim’s algorithm (also known as the DJP algorithm.) You can learn more about these and other algorithms and their history starting with this section of the Wikipedia page about MSTs, as well as the section Historical Notes from Applied Combinatorics by Keller and Trotter.
In 2002, Pettie and Ramachandran published a paper for an optimal minimum spanning tree algorithm.
15.3. Directed Trees
Recall that a tree is defined to be a connected simple graph that contains no cycles. The edges of a tree are undirected.
However, there are applications where it is useful to think of a tree as having directed edges. For that purpose, a directed tree is defined to be a directed graph whose underlying graph is a tree.
15.3.1. Rooted Trees
In some applications of directed trees, you can view the directed tree as if all paths “flow away” from a single vertex. For these applications, the concept of a rooted tree is useful.
The set of rooted trees can be defined recursively as follows.
| Basis Step |
A single vertex r is a rooted tree. The vertex r is called the root node of this rooted tree. |
| Recursion |
Suppose that you have a nonempty finite set of already-constructed rooted trees
(which will be called “old rooted trees” below)
such that the following propositions are True:
|
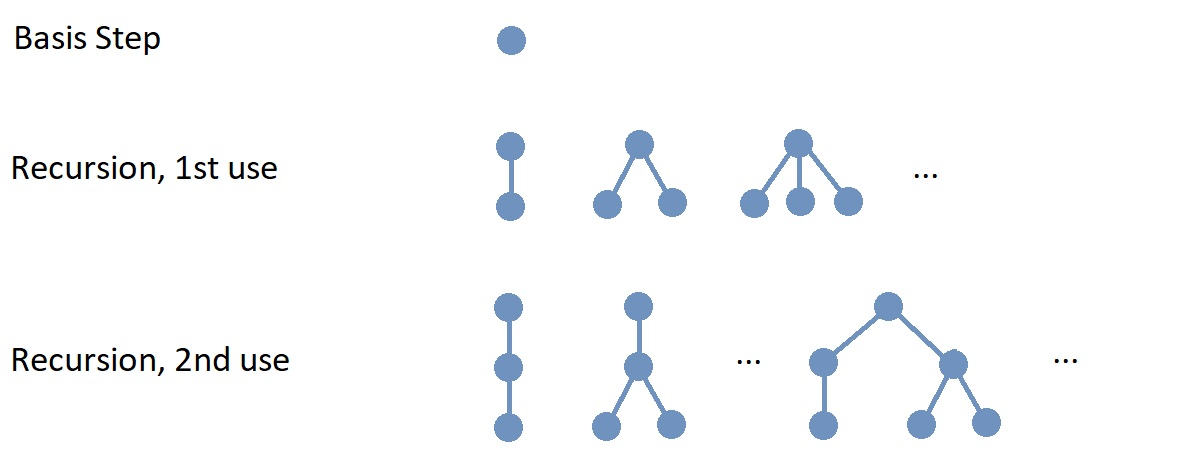
The image shows the basis step and represents, in part, the results of the first and second uses of the recursion step. In the image, the new root node created at each step is drawn at the top of the rooted tree.
| Notice that the directed edges of rooted trees are drawn without arrows! Computer scientists usually follow this convention: A rooted tree is drawn with the root node at the top, with all the old root nodes of the previously-constructed rooted trees attached in the Recursion step drawn at the same horizontal level beneath the root node. This convention, along with the recursive definition, ensures that the direction of each directed edge is “down,” so an arrow is not needed to determine the direction of edge. |
Notice that if you want to construct just one particular rooted tree, you only need to use the Recursion step finitely-many times. However, at each use of the Recursion step, there is an infinite number of possible rooted trees that can be constructed. Also, to construct all possible rooted trees would require infinitely-many uses of the Recursion step.
Some of the terminology used with rooted trees is borrowed from “family trees,” and other terminology is borrowed from plant science.
-
The new root node \(r\) added in the Recursion step is called the parent of each of the old root nodes, and each of the old root nodes is called a child of \(r.\) The old root nodes collectively are called the children of \(r.\)
-
Two or more nodes with the same parent are called siblings.
-
A node that has one or more children is called an internal node.
-
A node that has no children is called a leaf. A leaf can also be called an external node.
-
The depth of node \(v\) in a rooted tree is the length of the shortest path from the root node \(r\) to the node \(v.\) This is also called the level of the node \(v.\)
-
A level of a rooted tree is the set of all nodes at the same depth. For example, level 1 is the set of all the child nodes of the root node. Level 0 is the set containing only the root node.
-
The height of a rooted tree is the maximum of the depths of all the nodes in the rooted tree.
The next lemma shows that you can construct any rooted tree without using recursion by instead starting with a tree then replacing all the undirected edges by appropriately directed edges.
In summary, the lemma tells you that every rooted tree can be thought of as an adaptation of a tree, where you first select a vertex to be the root node and then replace all the edges of the tree by directed edges that “flow away” from the root node.
15.3.2. Ordered Trees
Notice that in the Recursion step of the definition of rooted tree, the new root node is connected to each of the old root nodes, but since the subtrees' roots are members of a set, the order in which the new root node is connected to the old root nodes is not important. However, in some applications of rooted trees, it is important to note the order in which the new root node is connected to the old root nodes.
For example, in a family tree, you may want to represent a person by the root node of the tree, then represent their offspring by birth order as the child nodes. In this case, the order of the children matters. To do this, you can list the old subtrees as the sequence \(T_{1}, \, \ldots \, T_{n}\) and list the old root nodes as the sequence \(r_{1}, \, \ldots \, r_{n},\) where \(n\) is the number of old subtrees used in the Recursion step.
In this subsection, a recursive definition for
ordered trees
is presented. This recursive definition takes the order of the indices of the old ordered trees into account when constructing the new ordered tree.
Warning: Many other names for ordered trees appear in various sources, such as
ordered rooted tree,
rooted plane tree,
RP-tree,
and
decision tree.
In fact, some sources even define “rooted tree” to mean what this textbook calls and “ordered tree.”
The set of ordered trees is defined recursively as follows.
| Basis Step |
A single vertex r is an ordered tree. Vertex r is the root node of this ordered tree. |
| Recursion |
Suppose that you have already constructed the ordered trees in the sequence \(T_{1}, \, \ldots \, T_{n}\) where \(n\) is a positive integer and for each positive integer \(i \leq n,\) the root node of \(T_{i}\) is the vertex \(r_{i}.\)
|
Ordered trees are usually drawn so that the root node appears at the top of the tree, and for each internal node, the children are drawn in order from left to right.
In summary, an ordered tree can be thought of as a special kind of rooted tree where the children of each internal node are ordered.
15.3.3. Isomorphisms: Rooted Trees and Ordered Trees
As discussed in the Graphs chapter, the definition of isomorphism can be adapted to include one-to-one correspondences between the vertex sets of two graphs that preserve specific features of a graph in addition to the adjacency relationships between vertices. Examples of such features are edge weights, edge directions, vertex colors, or edge colors.
In this subsection, examples are presented to show how the definition of isomorphism can be adapted for rooted trees and ordered trees.
Nonisomorphic Rooted Trees with Isomorphic Underlying Graphs
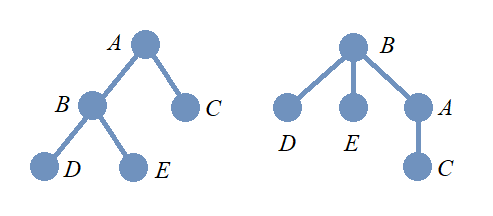
Here is a question for you: In the image, do the two drawings represent graphs or rooted trees? It’s okay if you are not sure how to answer this question. Since rooted trees are usually drawn with edges that do not use arrows to indicate the direction, the drawings are ambiguous, and you would probably need more context to decide whether the drawings represent two undirected graphs or two rooted trees.
Notice that the interpretation also effects whether the two drawings represent isomorphic objects.
-
Suppose that the drawings are interpreted as undirected graphs. These are isomorphic as undirected graphs, and also isomorphic as trees, since redrawing the graph on the left as the one on the right does not change the adjacency relationships of the vertices.
-
Suppose that the drawings are interpreted as rooted trees. The adjacency relationships are the same, but the direction of the edge with endpoints \(A\) and \(B\) depends on whether \(A\) or \(B\) is chosen as the root node. The underlying graphs with undirected edges are isomorphic, but the rooted trees are not isomorphic.
Nonisomorphic Ordered Trees that are Isomorphic Rooted Trees
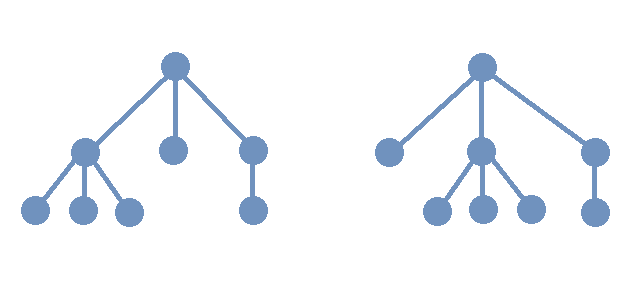
In the image, two rooted trees are shown. The two rooted trees are isomorphic as rooted trees since the order of the children of the root node does not matter. However, these two rooted trees are not isomorphic as ordered trees since the corresponding children are not in the same order in each rooted tree.
It may be helpful to think of each of the two ordered trees as “telling a story” about a family.
-
On the left, a parent has three children, and the oldest child has three children, the middle child has no children, and the youngest child has one child.
-
On the right, a parent has three children, and the oldest child has no children, the middle child has three children, and the youngest child has one child.
In general, ordered trees are isomorphic if and only if they tell the same story about the families, so these two are not isomorphic as ordered trees. On the other hand, they are isomorphic as rooted trees because they tell the same story when the birth order of the children at level 1 is ignored: A parent has three children, of whom one has three children, another one has one child, and yet another one has no children.
15.4. Binary Trees
| As mentioned near the beginning of this chapter, much of the terminology related to trees is not standardized. The definitions in this section use terminology consistent with Handbook of Graph Theory, Second Edition, but information on alternative definitions is also stated. |
For any positive integer \(m,\) an
m-ary tree
is defined to be
an ordered tree
in which each internal node has at most \(m\) children.
Some sources define m-ary tree to be a rooted tree instead of an ordered tree.
A
binary tree
is a 2-ary tree, or more simply, an ordered tree in which each internal node has at most two children. In a binary tree, the root node is the parent of at most two subtrees \(T_{1},\) called the
left subtree,
and \(T_{2},\) called the
right subtree.
Notice that in the context of binary trees, it is allowable for either or both of the subtrees to be absent (that is, empty).
Some sources allow a binary tree to be “empty,” in the sense that it has no vertices or edges. An “empty binary tree” is not an
ordered tree
as defined above since it has no root node. However, an empty binary tree is useful in computer science applications. For example, when implementing binary trees as data structures, an empty binary subtree corresponds to by a null pointer (or null reference); a leaf node of a binary tree can be recognized as a node whose left child and right child pointers/references are both null.
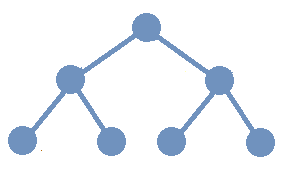
A
complete binary tree
is a binary tree in which every internal node has exactly 2 children and all leaves are at the same level.
Some sources
use either “perfect binary tree” or “full binary trees” to describe this type of binary tree and use the phrase “complete binary tree” to describe
something else.
A binary tree is called
balanced
if for every vertex \(v,\) the number of vertices in the left subtree of \(v\) and the number of vertices in the right subtree of \(v\) differ by at most one.
Some sources define a binary tree of height \(h\) to be balanced if each leaf is at either level \(h\) or level \(h − 1.\)
15.4.1. Tree Traversal Algorithms for Binary Trees
In many applications of binary trees, it is necessary to visit every node. The process of visiting every node is called tree traversal. In this subsection, you will learn about three commonly-used algorithms for tree traversal.
The three traversal algorithms can be described recursively as follows.
-
Preorder traversal: First, visit the root node. Secondly, visit each node in the root node’s left subtree using preorder traversal. Finally, visit each node in the root node’s right subtree using preorder traversal.
-
Inorder traversal: First, visit each node in the root node’s left subtree using inorder traversal. Secondly, visit the root node. Finally, visit each node in the root node’s right subtree using preorder traversal.
-
Postorder traversal: First, visit each node in the root node’s left subtree using postorder traversal. Secondly, visit each node in the root node’s right subtree using postorder traversal. Finally, visit the root node.
For each of these three traversal algorithms, the Base Step for the recursion
is applied to
a binary tree that has only one node
(a root node that has empty left and right subtrees),
and
you visit just that one node.
Some sources use hyphens in the written names of these traversal algorithms, so list them as
pre-order,
in-order,
and
post-order
traversal.
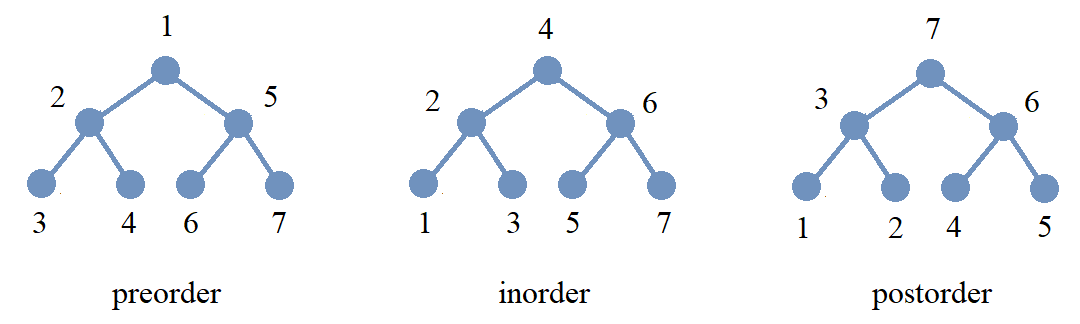
The image displays the same binary tree with its nodes being “counted off” using each of these three traversal algorithms.
You may find the interactive demonstration at this Wikipedia page useful to understanding these three traversal algorithms.
15.4.2. Binary Search Trees
Define a key to be an element of a set that has a total ordering. For example, keys could be integers ordered using the usual \(\leq\) relation. As another example, keys could be strings ordered alphabetically. In general, keys could be any type of data that can be totally ordered.
A binary search tree (BST) is a binary tree where each vertex is assigned a key in such a way that that if key \(k\) is assigned to vertex \(v\) then both of the following are True.
-
the key \(k\) is greater than each key assigned to a vertex in the left subtree of \(v,\) and
-
the key \(k\) is less than each key assigned to a vertex in the right subtree of \(v.\)
If you are given a list (or an array) of keys, a binary search tree can be used to sort the keys and then quickly search for a key. An advantage of binary search trees is that it is much easier and faster to maintain the sort order if you need to insert new keys than it would be to insert the same keys into a sorted list (or an array) of keys.
First, let’s construct a binary search tree from the list of keys \( \left[ 17, 3, 5, 31, 2 \right .\)]
-
The first key in the list, \(17,\) is assigned to the root node.
-
The next key, \(3,\) is less than the key \(17\) at the root node, so \(3\) is assigned to the left child of the root node.
-
The next key, \(5,\) is less than the key \(17\) at the root node, so \(5\) must be assigned to some node in the left subtree.
-
Since \(5\) is greater than the key \(3\) at the left subtree’s root, \(5\) is assigned to the right child of the left subtree’s root.
-
-
The next key, \(31,\) is greater than the key \(17\) at the root node, so \(31\) is assigned to the right child of the root node.
-
The last key, \(2,\) is less than the key \(17\) at the root node, so \(2\) must be assigned to some node in the left subtree.
-
Since \(2\) is less than \(3,\) \(2\) is assigned to the left child of of the left subtree’s root.
-
The following animation illustrates the construction of this binary search tree.

Now, let’s search for some keys. If a key is not already present, it will be inserted in the correct position.
Consider the key \(5.\)
-
\(5\) is less than the key at the root node, which is \(17.\) If \(5\) is in this BST, it must be in the left subtree, so continue searching from there.
-
\(5\) is greater than the key at the left subtree’s root node, which is \(3.\) If \(5\) is in this BST, it must be in the right subtree of this node, so continue searching from there.
-
\(5\) is equal to the key at the subtree’s root node, so we have found this key!
Now consider the key \(19\) which was not included in the original list.
-
\(19\) is greater than the key at the root node, which is \(17.\) If \(19\) is in this BST, it must be in the right subtree, so continue searching from there.
-
\(19\) is less than the key at the right subtree’s root node, which is \(31.\) If \(19\) is in this BST, it must be in the left subtree of this node, so continue searching from there.
-
This subtree is empty, so insert a new root node for this subtree and assign the key \(19\) to this new node.
The following image shows the modified BST with the new key \(19\) inserted in the correct position.
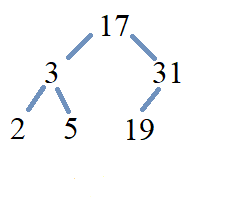
Locate the correct position of the new node when the key \(11\) is inserted in the previously modified BST.
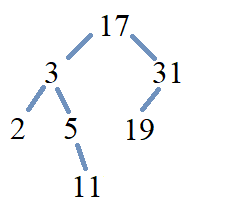{kind=link}
Constructing a binary search trees from a list can serve two purposes. First, as shown in the preceding example, it is quicker to search for a key in the binary search tree because, in the best case scenario when the tree is balanced, the number of keys is halved with each iteration of the search. Secondly, the original list can be sorted by performing an inorder traversal of the binary search tree.
Consider the binary search tree with integer keys that was the solution in the “You Try” section of the previous example.

List the keys of the binary search tree using each of preorder, inorder, and postorder traversal to visit all nodes of the binary search tree.
Inorder: \( \left[ 2, 3, 5, 11, 17, 19, 31 \right .\)]
Preorder: \( \left[ 2, 11, 5, 3, 19, 31, 17 \right .\)]
Here is another exercise for you to try.
{kind=link}
15.4.3. Expression Trees and Polish Notation
In the 1920’s, the Polish logician Jan Łukasiewicz created a notational format for writing logical well-formed formulas that does not use any parentheses: Instead of writing logical operator symbols (like \(\land\) and \(\lor\)) between two previously-constructed wffs, Łukasiewicz placed operator symbols in front of those wffs, which makes the use of parentheses completely unnecessary! Today, notation that is based on Łukasiewicz’s original notation is called either Polish notation or prefix notation and is applied to both arithmetic/algebraic formulas and logical formulas.
There is also the Reverse Polish notation, also called postfix notation, where the operator symbol is placed after its operands. The “usual” notation where the operator symbol is placed between the two operands is called infix notation.
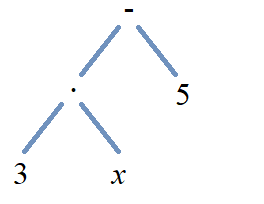
You can use binary trees and tree traversal to make it easier to switch between these three notations. Define an expression tree to be a binary tree where each leaf is labeled by either a numeral or a variable symbol, and where each internal node is labeled by an operator symbol. The expression tree for the infix notation \(3 \cdot x - 5\) is shown. Notice that in the expression tree for \(3 \cdot x - 5,\) the root node corresponds to the “last” operation you would perform and the subtrees correspond to the previously-constructed expressions \(3 \cdot x\) and \(5.\) Also notice that, in the earlier example, the order of the symbols for the infix expression corresponds to the inorder traversal of the expression tree. It is an exercise for you to confirm that the order of the symbols in the Polish notation expression corresponds to the preorder traversal of the expression tree, and that the Reverse Polish notation expression corresponds to the postorder traversal of the expression tree.
Consider the arithmetic expression. \[ 5 + 7 \times - 3 - 8 \div 2 \] Recall that it is not correct to evaluate this left-to-right; instead you need to use the order of operations, which is equivalent to evaluating the following expression that results after inserting parentheses. \[ (5 + (7 \times (- 3))) - (8 \div 2) \] From this second expression, you can see that the expression tree will have the minus sign at the root and subtrees that represent \((5 + (7 \times (- 3)))\) and \((8 \div 2).\) Continuing recursively, the subtree for \((5 + (7 \times (- 3)))\) will have the plus sign at its root and subtrees that represent \(5\) and \((7 \times (- 3)),\) and the subtree for \((8 \div 2)\) will have the division sign at its root node and subtrees that represent \(8\) and \(2.\) Continue recursively until all symbols have been placed at a node.
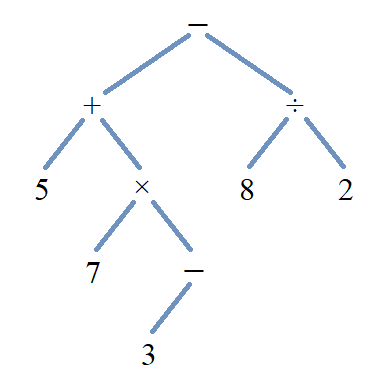
The image displays a drawing of the expression tree for \((5 + (7 \times (- 3))) - (8 \div 2)\). Notice that the negative sign labels a node with only one child, which is treated as the left child (but as the right child for inorder traversal. )
Next, you can use each of the traversal methods to create the Polish (prefix), infix, and Reverse Polish (postfix) expressions.
\(\text{prefix: } \ - \, + \, 5 \, \times \, 7 \, - \, 3 \, \div \, 8 \; 2 \)
\(\text{infix: } \ 5 \, + \, 7 \, \times \, - \, 3 \, - \, 8 \, \div \, 2 \)
\(\text{postfix:} \ 5 \, 7 \, 3 \, - \, \times \, + \, 8 \; 2 \, \div \, - \)
You can see another example of how to construct expression trees, using Reverse Polish notation and a stack, at this Wikipedia page.
15.4.4. Isomorphisms: Binary Trees
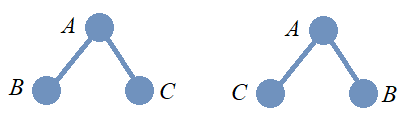
In the image, two binary trees are shown. As binary trees are ordered trees, it should be clear that these cannot be isomorphic as binary trees because the order of the left and right children of the root node in the two trees are different.
15.5. Additional Topics To Be Added Later
-
Algorithms for depth-first and breadth-first traversal
-
For now, you can visit the following two links at Simple English Wikipedia for the basic definitions of depth-first search (DFS) and breadth-first search (BFS).
Note that each of preorder, inorder, and postorder traversal is an example of a depth-first traversal.
As an example of breadth-first search, consider finding a shortest path between two vertices of a connected undirected graph (e.g., first assign each edge a weight of \(1,\) then use Dijkstra’s Algorithm to find the path of minimal total weight between the two vertices, that path is the shortest path.)
-